《FluentPython2ndEdition》-第一部分
第一章 Python数据模型
- 通过特殊方法利用Python数据模型,这样做有两个优点
- 类的用户不需要记住标准操作的方法名称。
- 可以充分利用Python标准库,例如random.choice函数,无需重复发明轮子。
特殊方法是如何使用的?
要明确一点,特殊方法供Python解释器调用,而不是你自己。也就是说,没有 my_object.len()这种写法,正确的写法是len(my_object)。
特殊方法的重要用途:
模拟数值类型
__abs__获取对象的绝对值
mul、__add__返回一个新的Vector实例,没有修改运算对象,只读取self或other。
对象的字符串表示形式
__repr__获取对象的字符串表现形式。
Vector类__repr__方法中的f字符串使用!r以标准的表示形式显示属性。
于此形成对照的是__str__方法由内置函数str()调用,在背后供print()函数使用,返回对终端用户友好的字符串。
如果你熟悉的边程序语言使用ToString()方法,你可能习惯实现__str__方法,而不是__repr__方法。在Python中如果必须二选一的话,请选择__repr__方法。
对象的布尔值
默认情况下,用户定义类的实例都是真值,除非实现了__bool__或__len__方法。
容器API
每一个容器类型均应实现如下事项
- Iterable要支持for、拆包和其他迭代方式
- Sized要支持内置函数len
- Container要支持in运算符
Python不强制要求具体类继承这些抽象基类中的任何一个。这要实现了__len__方法,就说明那个类满足Sized接口。
Collection有3个非常重要的专用接口
- Sequence规范和list和str等内置类型的接口
- Mappingi被dict、collections.defaultdict等实现
- Set是set和frozenset两个内置类型的接口
len为什么不是方法
因为经过了特殊的处理,被当作Python数据模型的一部分,就像abs函数一样。但是借助特殊方法__len__,也可以让len适用于自定义对象。这是一种相对公平的折中方案,既满足了对内置对象速度的要求,又保证了语言的一致性。
延伸阅读 Python语言参考手册
第二章 丰富的序列
深入理解Python中不同的序列类型,不但能避免重新发明轮子,还可以从他们共通的接口上受到启发,在自己实现API时合理支持及利用现有和将来可能添加的序列类型。
内置序列概览
容器序列
可存放不同类型的项,其中包括嵌套容器。例如 list、tuple 和 collections.deque。
存放的是对象的引用,对象可以是任意类型。
扁平序列
可存放一种简单类型的项,例如 str、bytes 和 array.array。
在自己的内存空间中存储所含内容的值,而不是各自不同的Python对象。
列表推导式和生成器表达式
使用列表推导式(目标是了列表)或生成器表达式(目标是其他序列类型)可以快速构建一个序列。
使用这两种句法写出的代码更容易理解,速度通常更快。
列表推导式涵盖map和filter两个函数的功能。
生成器一次产出一项提供给for循环,如果是两个各有1000项的列表,则使用生成器表达式计算笛卡尔积可以节省大量内存,因为不用先构建一个包含100万项的列表提供给for循环。
元组不仅仅是不可变列表
元祖有两个作用,除了可以作为不可变列表外,还可用作没有字段名称的记录。
一般使用_表是虚拟变量
Python解释器和标准库经常把元祖当做不可变列表使用,这样做意图清晰(只要在源码中见到元组,你就知道它长度不可变),性能优越。
元祖的不可变性仅针对元祖中的引用而言。元祖中的引用不可删除,不可替换。倘若引用的时可变对象,改动对象之后,元祖的值也会随之变化。存放可变项的元组可能会导致bug。
序列和可迭代对象拆包
拆包的特点是不用我们自己动手通过索引从序列中提取元素,这样就减少了出错的可能。
拆包的目标可以是任意可迭代对象。
定义函数时可以使用*args捕获余下的任意数量的参数,这是Python的一个经典特性。
序列模式匹配
match关键字后面的表达式是 匹配对象 ,即各个case字句中尝试匹配的数据。
case _ 是默认的case语句,相当于C#中的default。
表面上看,match/case与C语言中的switch/case语法很相似。与swith相比,match的一大改进时支持 析构,这是一种高级拆包形式。
在match/case上下文中,str、bytes和bytearray实例不作为序列处理。match把这些类型视为原子值,就像证书987被视为一个整体值,而不是数字序列。
与拆包不同,模式不析构序列意外的可迭代对象。
添加类型信息可以让模式更加具体。
以if开头的卫语句是可选的,仅当匹配模式时才运行。
模式匹配是一种声明式编程风格,即描述你想匹配什么,而不是如何匹配,这样写出的代码结构与数据结构是一致的。
18.3节还会进一步分析lis.py,届时将全面研究evaluate中的match/case语句,如果想要深入了解lis.py,可阅读Norvig写的文章:“(How to Write a (Lisp)Interpreter (in Python)) ”。
切片
本节讨论切片的高级用法。
为什么切片和区间排除最后一项
切片和区间排除最后一项是一种Python风格约定,有以下好处
- 在仅指定停止位置时,容易判断切片或区间的长度。
- 同时指定起始和停止位置时,容易计算切片或区间的长度,做个减法即可:stop - start。
arr = [10,20,30,40,50,60]
arr[:2] 代表从开始位置到索引2截止,排除最后一项 arr[2:] 代表从索引2开始到最后位置截止,包含最后一项
还可以使用arr[a:b:c]句法来制定步距c,让切片跳过部分项。步距也可以是负数,反向返回项。
a:b:c表示法只在[]内部有效,表是索引或下标索引。
多维切片和省略号
例如,在外部包numPy中,numpy.ndarray表示的二维数组可以使用a[i,j]句法获取数组中的元素,还可以使用表达式a[m:n, k:l]获取二维切片。
NumPy在处理多位数组切片时把…解释为一种快捷句法。例如,对四位数组x x[i, …]是x[i, :, :, :]的快捷句法。
为切片赋值
在赋值语句的左侧使用切片表示法,或者作为del语句的目标,可以就地移植、切除或以其他方式修改可变序列。
如果赋值目标是一个切片,则右边必须是一个可迭代对象,即便只有一项。
使用 + 和 * 处理序列
+和 * 始终创建一个新对象,绝不更改操作数
初始化潜逃列表可以使用 * 运算符,例如 board = [[‘_’] * 3 for i in range(3)]
对不可变序列重复拼接效率低下,因为解释器必须复制整个目标序列,创建一个新序列,包含要拼接的项,而不是简单追加新项
不要在元组中存放可变的项
增量赋值不是原子操作。
检查Python字节码不太难,从中可以看出Python在背后做了什么。
list.sort与内置函数sorted
list.sort方法就地排序列表,即不创建副本,返回值为None,目的就是提醒我们,它更改了接收者,没有创建新列表。这是PythonAPI的一个重要约定:就地更改对象的函数或方法应该返回None,让调用方清楚地知道接收者已被更改,没有创建新对象
与之相反,内置函数sorted返回创建的新列表。该函数接收任何可迭代对象作为参数,包括不可变序列生成器。无论传入什么类型的可迭代对象,sorted函数始终反悔新创建的列表。
顺便说一下,使用key参数,哪怕掺杂数值和类似数值的字符串,也可以排序。我们只需要决定把所有项全都视为整数还是字符串。
当列表不适用时
array
使用数组处理上百万个浮点数可以节省大量内存。数组支持所有可变序列操作,此外还有快速加载项和保存项的方法。
从Python3.10开始,array类型没有列表那种就低排序方法sort,如果需要排序,请使用内置函数sorted重构数组。原因可能是数组是存储在连续的空间内,使用sort方法原地排序性能开销较大。
memoryview
内置的memoryview类型是一种共享内存的序列类型,可在不复制字节的情况下处理数组的切片。
memoryview是NumPy中一种普遍使用的结构,本质上就是Python中的数组。memoryview在数据结构(例如PIL图像、SQLite数据库、NumPy数组等)之间共享内存,而不是事先复制,这对大型数据集来说非常重要。
如果要对数组做一些高级数值处理,应该使用NumPy库。
NumPy
科学计算需要经常做一些高级数组和矩阵运算,得益于NumPy,Python成为这一领域的主流语言。NumPy实现了多维同构数组和矩阵类型,除了存放数值外,还可以存放用户定义的记录,而且提高了高效的元素层面操作。
NumPy和SciPy这两个库功能异常强大,为很多优秀的工具提供了坚实的基础,例如Pandas和scikit-learn。
双端队列和其他队列
列表可以当做栈或队列使用,但是插入和删除项有一定开销,因为整个列表都必须在内存中移动。
collections.deque类实现一种线程安全的双端队列,旨在快速在两端插入和删除项。
除了deque外,Python标准库中的其他包还实现了以下队列
- queue
- multiprocessing
- asyncio
- heapq
第三章 字典和集合
Python中的字典能如此高效,要归功于 哈希表。
除了字典外,内置类型中的set和frozenset也基于哈希表。
字典的现代用法
字典推导式 从任何可迭代对象中获取键值对,构建dict实例。
调用函数时,不止一个参数可以使用**。但是,所有键都要是字符串,而且在所有参数中是唯一的。
**可以在dict字面量中使用,同样可以多次使用。这种情况下允许键重复,后面的键覆盖前面的键。
使用|合并映射
| Python3.9支持 | 和 | =操作符合并映射。因为两者也是并集运算符。 |
| 使用 | 运算符创建一个新映射,通常新映射的类型与左操作数的类型相同。 |
| 如果想就地更新因故射,则使用 | =运算符。 |
使用模式匹配处理映射
不同类型的模式可以组合和嵌套,不同类型的模式可以组合和嵌套。借助析构可以处理嵌套和序列等结构化记录。我们经常需要从Json API和具有半结构化的数据库中读取这类记录。
模式中键的顺序无关紧要。
倘若你想把多出的键值对捕获到一个dict中,可以在一个变量前面加上**,不过必须放在模式最后。
映射类型的标准API
可哈希指的是什么?
如果一个对象的哈希玛在整个生命周期内永不改变(依托__hash__方法),而且可与其他对象比较(依托__eq__方法),那么这个对象就是可哈希的。两个哈希对象仅当哈希玛相同时相等。
数值类型和不可变的扁平类型str和bytes都是可哈希的。
一个对象的哈希玛根据所用的Python版本和设备架构有所不同。正确实现的对象,其哈希玛在一个Python进程内保持不变。
插入或更新可变的值
根据Python的快速失败原则,当键k不存在时,d[k]抛出错误,如果需要默认值,可以把d[k]换成d.get(k, default)。这样写并不完美,最好使用d.setdefault(key,[]).append(value)。
自动处理缺失的键
人为设置默认值有两种办法:第一种是把普通的dict换成defaultdict,第二种是定义dict或其他映射类型的子类,实现__missing__方法。
defaultdict:处理缺失键的另一种选择
实现的原理是,实例化defaultdict对象时提供一个可调用对象,当__getitem__遇到不存在的键时,调用那个可调用对象生成一个默认值。
举个例子,假设使用 dd = defaultdict(list)创建一个defaultdict对象,而且dd中没有”new-key”键,那么dd[“new-key”]表达式按以下几步处理。
- 调用list()创建一个新列表
- 把该列表插入dd,对应到’new-key’键上。
- 返回该列表的引用。
__missing__方法
映射处理缺失键的底层逻辑在__missing__方法中。dict基类本身没有定义这个方法,但如果dict的子类定义了这个方法,那么dict.__getitem__找不到键时将调用__mingssing__方法,不抛出KeyError。
自己定义的类,如果继承标准库中的映射,在实现__getitem__、get或__contains__方法时不一定要回落到__missing__方法,因为标准库对missing__方法的使用不一致。
dict子类只实现__mingssing方法,其他均不实现。
collections.UserDict子类,同样实现__missing__方法,其他均不实现。继承自UserDict的get方法调用__getitem。在查找键时可能会调用missing方法。
abc.Maaping子类,以最简单的方式实现__getitem__方法
abc.Mapping子类,实现__getitem__方法,并定义__missing__方法。
dict的变体
collections.OrderedDict
自Python3.6起,内置的dict也保留键的顺序,使用OrderedDict的主要原因是编写与早期Python版本兼容的代码。
collections.ChainMap
ChainMap实例存放一组映射,可作为一个整体来搜索。此实例不复制输入映射,而是存放映射的引用。
collections.Counter
这是一种对键计数的映射。更新现有的键,计数随之增加。可用于统计可哈希对象的实例数量,或者作为多重集使用。
shelve.Shelf
标准库中的shelve模块持久存储字符串键与Python对象之间的映射。
shelve.Shelf时abc.MutableMapping的子类,提供了我们预期的映射类型的基本方法。
shelve.SHelf还提供了一些其他I/O管理方法,例如sync和close。
Shelf实力是上下文管理器,因此可以使用with块确保在使用后关闭
子类应继承UserDict而不是dict
创建新的映射类型,最好扩展collections.UserDict而不是dict,主要原因是,内置的dict在实现上走了一些捷径,如果继承dict,那就不得不覆盖一些方法,而继承UserDict则没有这些问题。
要注意的是,UserDict没有继承dict,使用的是组合模式:内部有一个dict实例,名为data,存放具体的项。
由于UserDict扩展abc.MutableMapping,因此使StrKeyDict成为一种功能完整的映射方法,是从UserDict、MutableMapping或Mapping继承的方法。
不可变映射
types模块提供的MappingProxy是一个包装类,把传入的映射包装成一个mappingproxy实例,这是原映射的动态代理,只可读取。
字典试图
视图对象是动态代理。更新原dict对象后,现有视图立即能看到变化。
dict的实现方式对实践的影响
Python使用哈希表实现dict,因此字典的效率非常高,不过这种设计对实践也有一些影响,不容忽视。
- 键必须是可哈希的对象。
- 通过键访问项速度非常快。
- 在CPython 3.6中,dict的内存布局更为紧凑,顺带的一个副作用是键的顺序得以保留。
- 尽管采用了新的紧凑布局,但是字典仍占用大量内存,这是不可避免的。
- 为了节省内存,不要在__init__方法之外创建实例属性。
集合论
集合是一组唯一的对象,集合的基本作用就是去除重复项。
集合元素必须是可哈希的对象。set类型不可哈希,因此不能构建嵌套set实例的set对象。但是fronzenset可哈希,所以set对象可以包含frozenset元素。
| 除了强制唯一性以外,集合类型通过中缀运算符实现了许多集合运算。给定两个集合a和b,a | b是a和b的并集,a&b是a和b的交集,a-b是a和b的差集,a^b是a和b的对称差集。 |
set字面量
set字面量的句法与集合的数学表示法几乎一样
创建空set,务必使用不带参数的构造函数,即set。
frozenset没有字面量句法,必须调用构造函数创建。
集合推导式
集合推导式用法: {chr(i) for i in range(32, 256) if ‘SIGN’ in name(chr(i), ‘’))
集合的实现方式对实践的影响
set和frozenset类型都使用哈希表,这种设计带来了以下影响:
- 集合元素必须是可哈希的对象。
- 成员测试效率非常高
- 与存放元素指针的底层数组相比,集合占用大量内存。
- 元素的顺序取决于插入顺序,但是顺序对集合没有意义,也得不到保障。
- 向集合中添加元素后,元素的顺序可能会发生变化。
dict_keys视图始终可以当做集合使用,因为按照其设计,所有键均可哈希。
使用集合运算符处理视图可以省去大量的循环和条件判断。
第四章Unicode文本和字节序列
本章讨论Unicode字符串、二进制序列,以及在二者之间转换时使用的编码。
字符问题
字符串是个相当简单的概念:一个字符串就是一个字符序列。问题出在字符的定义上。
在2021年,字符的最佳定义是Unicode字符。因此,从Python3的str对象中获取的项是Unicode字符。
Unicode标准明确区分字符的标识和具体的字节表述。
字符的表示即码点,是0~1114111范围内的数(十进制),在Unicode标准中以4~6个十六进制数表示,前加“U+”,取值范围是U+0000~U+10FFFF。。
字符的具体表述取决于所用的编码。编码是在码点和直接系列之间转换时使用的算法。例如,字母A(U+0041)在UTF-8编码中使用单个字节\x41标书,而在UTF016LE编码中使用字节序列\x41\x00表述。再比如,欧元符号(U + 20AC)在UTF-8编码中需要3个字节,即\xe2\x82\xac,而在UTF-16LE中,同一个码点编码成两个字节,即\xac\x20。
把码点转为字节序列的过程叫编码,把字节序列转为码点的过程叫解码。
字节概要
Python内置两种基本的二进制序列类型:bytes和bytearray。
bytes和bytearray中的项是0~255范围内的整数。然而,二进制序列的切片始终是同一类型的二进制序列,包括长度为1的切片。
构建bytes和bytearray实例可以调用各自的构造函数,传入以下参数
一个str对象和encoding关键字
一个可迭代对象,项为0-255范围内的数
一个实现了缓冲协议的对象。构造函数把源对象中的字节序列复制到新创建的二进制序列中。
基本的编码解码器
Python自带超过100种编码解码器(codec, encoder/decoder),用于在文本和字节之间相互转换。
处理编码和解码问题
UnicodeError是一般性的异常,Python在报告错误时通常更具体,抛出UnicodeEncodeError或UnicodeDecodeError。。如果源码的编码与预期不符,那么加载Python模块时还可能跑出SyntaxError。
多数非UTF编码解码器只能处理Unicode字符的小部分子集。把文本转换成字节序列时,如果目标编码没有定义某个字符,则会抛出UnicodeEncodeError,除非把errors参数传递给编码方法或函数,做特殊处理。
并非所有字节都包含有效的ASCII字符,也并非所有字节序列都是有效的UTF-8或UTF-16码点。
如何找出字节序列的编码
简单来说,不能,只能由别人来告诉你。
有些通信协议和文件格式,例如HTTP和XML,通过首部明确指明内容编码。如果字节流中包含大于127的字节值,则可以肯定,用的不是ASCII编码。另外,按照UTF-8和UTF-16编码的设计方式,可用的字节序列也受到限制。
就像人类的语言也有规则和限制一样,只要假定字节流是人类可读的纯文本,就可能通过试探和分析找出编码。
BOM:有用的鬼符
UTF-16编码的开头有几个额外的自己,例如:b’\xff\xfeE\x001\x00\x00N。其中xfe指得就是BOM,即字节序标记(byte-order mark),指明编码时使用Intel CPU的小端序。
在小端序设备中,各个码点的最低有效字节在前面。在大端序CPU中,编码顺序反过来,’E’被编码为0和69。
UTF-16有两个变种:UTF-16LE,显示指明使用小端序;UTF-16BE,显示指明使用大端序。如果直接指明使用这两个变种,则不生成BOM。
处理文本文件
Unicode三明治:输入时解码字节序列;中间层只处理文本;输出时编码文本。
Python3中,可以轻松采纳Unicode三明治的建议,因为内置函数open()在读取文件时会做必要的解码,以文本模式写入文件时还会做必要的编码,所以调用my_file.read()方法得到的以及my_file.write()方法传入的都是str对象。
在Python中,I/O默认使用的编码受到几个设置的影响。
总结一下编码:
- 打开文件时如果没有指定encoding参数,则默认编码由locale.getpreferredencoding()函数决定。
- 在二进制数据与str之间转换时,Python内部使用sys.getfilesystemencoding()函数决定编码。该设置不可更改。
- 编码和解码文件名使用sys.getfilesystemencoding()函数决定。
locale.getpreferredencoding()函数根据用户偏好设置,返回文本数据的编码。用户偏好设置在不同的系统中以不同的方式设置,而且在某些系统只可能无法通过编程方式设置,因此这个函数返回的只是猜测的编码。
因此,关于默认编码的最佳建议:别依赖默认编码。
为了正确比较而规范化Unicode字符串
因为Unicode有组合字符,所以字符串比较起来比较复杂。解决方案是使用unicodedata.normalize()函数。该函数的第一个参数是NFC、NFD、NFKC和NFKD之一,表示要使用的规范。
大小写同一化
就是把所有文本都转为小谢,再做些其他转换。这个操作由str.casefold()函数完成。
规范化文本匹配的实用函数
如果需要处理多语言文本,应该使用nfc_equal和fold_equal函数。
极端“规范化”:去掉变音符
去掉变音符不是正确的规范化方式,因为这往往会改变词的意思,而且可能让人误判搜索结果。
Unicode文本排序
给任何类型的序列排序,Python都回注意比较序列中的每一项。对字符串来说,比较的是码点。可是,遇到飞ASCII字符,比较就会出错。
在Python,非ASCII文本的标准排序方式是用locale.strxfrm函数。这个函数“把字符串转成适合所在区域进行比较的形式”。
Unicode数据库
Unicode标准提供了一个完整的数据库(许多结构化文本文件),不仅包括码点名称之间的映射表,还包括各个字符的元数据,以及字符的关系。
unicodedata.category()返回char在Unicode数据库中的类别。
按名称查找字符
unicodedata模块中有几个函数用于获取字符的元数据。例如unicodedata.name()返回一个字符在标准中的官方名称。
字符的数值意义
unicodedata模块中有几个函数可以检查Unicode字符是不是不表示数值,如果是的话还能确定人类可读的具体数值,而不是码点数。unicodedata.name()和unicodedata.numeric()函数,以及str的.isdecimal()和.isnumeric()方法。
支持str和bytes的双模式API
Python标准库中的一些函数能接受str或bytes为参数,根据其具体类型的不同展现不同的行为。
第五章数据类构建器
Python提供了几中构建简单类的方式,这些类只是字段的容器,几乎没有额外功能。这种模式被称为“数据类”(data class),dataclass包就支持该模式。以下是三个可简化数据类构建过程的构建器。
最简单的构建方式,从Python2.6开始提供。
写法: from collections import namedtuple Coordinate = namedtuple(‘Coordinate’, ‘lat lon’)
typing.NamedTuple 另一种构建方式,需要为字段添加类型提示,从Python3.5开始提供。
写法: import typing Coordinate = typing.collections.namedtupleNamedTuple(‘Coordinate’, [(‘lat’, float), (‘lon’, float)])
这种方式可读性高,而且可以通过映射指定字段及类型,再使用**fields_and_types拆包。
@dataclasses.dataclass 一个类装饰器,与前两种相比,可定制的内容更多,增加了大量选项,可实现更复杂的功能,从Python3.7开始提供。
写法: from dataclasses import dataclass
@dataclass class Coordinate: lat: float lon: float
区别在于class语句上,@dataclass装饰器不依赖继承或元类,如果你想使用这些机制,则不受影响。
3个数据类构建器有许多主要功能如下:
- 可变实例
- 3个数据类构建器之间的主要区别在于,collections.namedtuple和typing.NamedTuple返回不可变实例,而@dataclass返回可变实例。
- class语句句法
- 只有typing.NamedTuple和@dataclass支持class语句,方便为构建的嘞增加方法和文档字符串。
- 构造字典
- 两种具名元组都提供了构造dict对象的实例方法(.asdict),可根据数据类实例的字段构造字典。
- 获取字段名称和默认值
- 3个类构建器都支持获取字段名称和可能配置的默认值。
- 获取字段类型
- typing.NamedTuple和@dataclass定义的类有一个__annotations__属性,返回名称到类型的映射。使用typing.get_type_hints()函数获取。
更改之后创建新实例
- 运行时定义新类
典型的具名元组
collections.namedtuple是一个工厂函数,用于构建增强的tuple子类,具有字段名称、类名和提供有用信息的__repr__方法。namedtuple构建的类可在任何需要使用元组的地方使用。
from collections import namedtuple
City = namedtuple(‘City’, ‘name country population coordinates’)
tokyo = City(‘Tokyo’, ‘JP’, 36.993, (35.689722, 139.691667))
创建元组nametuple需要制定两个参数:一个类名和一个字段名称列表。后一个参数可以是产生字符串的可迭代对象,也可以是一整个以空格分割的字符串。
字段名称必须以单个位置参数传递给构造函数,可以通过名称或者位置访问字段。
带类型的具名元组
from typeing import NamedTuple
class Coordinate(NamedTuple): lat: float lon: float reference: str = ‘WGS84’
每个字段都要注解类型
实例字段reference注解了类型,还指定了默认值
使用typing.NamedTuple构建的类,拥有的方法并不比collections.namedtuple生成的更多,而且同样也从tuple集成方法。唯一的区别是多了类属性__annotations__,而在运行时,Python弯曲忽略该属性。
typing.NamedTuple的主要功能是类型注解。
类型提示入门
首先你要知道,Python字节码编译器和解释器并不强制要求你提供类型信息。
Python的类型提示可以看作是:供IDE和类型检查工具验证类型的文档。这是因为类星体是其实对Python程序的运行时没有影响。
类型提示主要是为了第三方类型检查工具提供支持,例如Mypy和PyCharm IDE内置的类型检查器。这些都是静态分析工具,在静止状态下检查Python源码,不运行代码。
类属性是描述符,后续章节会讲到,现在可以把描述符理解为特性(property)读值(getter)方法,即不带调用运算符()的方法,用于读取实例属性。元组是不可变的。
@dataclass详解
@dataclass为Python数据类装饰器,主要用于建华数据类的创建过程,减少了样板代码。适用于需要大量数据存储和处理的场景,如配置文件、数据库模型等。
这个装饰器接受叫多个关键参数,完整签名如下:
@datasclass(*, init=Ture, repr=True, eq=True, order=False, unsave_hash=False, frozen=False)
第一个参数*表示后面都是关键参数。
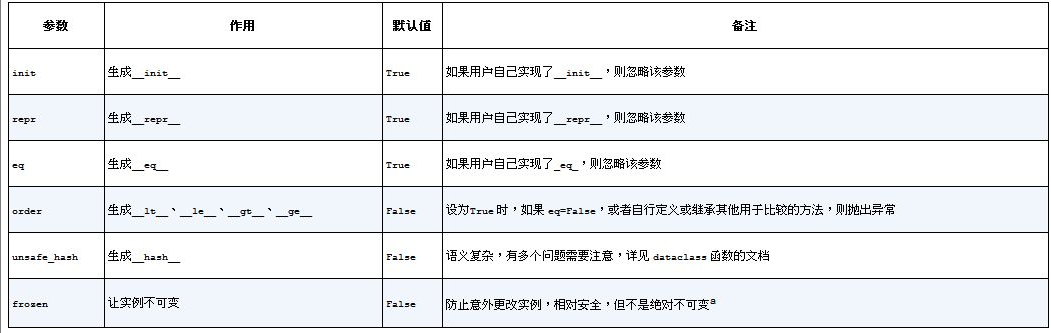
Python规定,带默认值的参数后面不能由不带默认值的参数。类属性通常用作实例属性的默认值,数据类也是如此。
类属性通常用作实例属性的默认值,数据类也是如此。@dataclass使用类型中的默认值生成传给__init__方法的参数默认值。
在设计可变对象如列表时,为确保@dataclass能正确处理默认值,需要采取一些额外的措施。因为默认值是共享的,如果不使用default_factory,可能会导致默认值重复的问题。
default_factory是field最常用的参数。
@dataclass应该只做一件事:把传入的参数及其默认值(如未指定值)赋值给实例属性,变成实例字段。可是,有时候初始化实例要做的不止这些,这时候就可以通过__post_init__方法。如果存在这个方法,则@dataclass将在生成的__init__方法最后调用__post_init__。
有时,也需要把需要把不作为实例字段的参数传给__init__方法。这种参数叫“仅作初始化的变量”(init-only variable)。为了声明这种参数,dataclass模块提供了伪类型InitVal。
@dataclass Class C: i : int j : int = None database : InitVal[DatabaseType] = None def post_init(self, databse): if self.j is None and database is not None: self.j = database.lookup(‘j’) c = C(10, databse = my_aatabase)
InitVal阻止@dataclass把Database视为常规字段,因此dataclass不会被设为实例属性,也不会出现在dataclass.fields函数返回的列表中。然而,对于生成的__init__方法,database是参数之一,同时也会传给__post_init__方法。
@dataclass示例:都柏林核心模式
都柏林核心(Dublin Core)模式是一个小组术语,可用于描述数字资源,也可用于描述物理资源,例如图书、CD和艺术品等对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from dataclasses import dataclass, field
from typing import Optional
from enum import Enum, auto
from datetime import date
class ResourceType(Enum):
BOOK = auto()
EBOOK = auto()
VIDEO = auto()
@dataclass
class Resource
"""描述媒体资源"""
identifier: str
title: str = '<untitled>'
creators: list[str] = filed(default_factory=list)
date: Optional[date] = None
type: ResourceType = ResourceType.BOOK
description: str = ''
language: str = ''
subjects: list[str] = field(default_factory=list)
数据类的确很方便,但是如果过度使用,也会为你的项目带来不好的影响.
数据类导致代码异味
所谓数据类是指他们拥有一些字段,以及用于访问(读写)这些字段的函数,除此之外一无长物。这样的类只是一种不会说话的数据容器,它们几乎一定被其他类过分繁琐地操控着。
面向对象编程的主要思想是把行为和数据放在同一个代码单元(类)中。如果一个类使用广泛,但是自身没有什么重要的行为,那么整个系统可能遍布处理示例的代码,并出现在很多方法和函数中。
有几种情况适合使用没什么行为或者没任何行为的数据类:
- 把数据类用作脚手架
- 把数据类用作中间表述
模式匹配类实例
类模式通过类型和属性(可选)匹配实例。类模式的匹配对象可以是任何类的实例,而不是仅仅是数据类的实例。
类模式有三种变体:简单类模式、关键字类模式和位置类模式。
5.9本章小结
本章主要讲了三个数据类构建器:collections.namedtuple、typing.NamedTuple和dataclasses.dataclass。每个构建器都可以根据给工厂函数的参数生成数据类,后两个构建器还可以通过class语句提供类型提示。两种具名元组变体生成的书tuple子类,与普通的元组相比,增加了通过名称访问字段的功能,另外还提供了一个类属性_fields,以字符串元组的形式列出字段名称。
第六章 对象引用、可变性和垃圾回收
变量不是盒子
在面相对象编程语言的引用式变量中,变量不是盒子指的是,b = a,只是把a的引用给b,而不是把a的值复制给b。把变量想成盒子无法理解这个行为,影响想成便利贴,b = a 只是在a上贴了一个便利贴b。
同一性、相等性和别名
对象一旦创建,其标识始终不变。可以把标识理解为对象在内存中的地址。is运算符比较两个对象的标识,id()函数返回对象标识的整数表示。
实际编程中很少使用id()函数。对象的标识最常使用is运算符比较,无须直接调用id()函数。
元组(tuple)的相对不可变性
元组与多数Python容器(集合、字典、列表等)一样,存储的是对象的引用,如果引用的项是可变的,即使元组本身不可变,项也可以更改。也就是说元组的不可变形其实是指tuple数据结构的物理内容不可变,与引用对象无关。
默认做浅拷贝
复制列表(多数内置的可变容器)最简单的办法就是使用内置的构造函数。也可以使用[:]来创建副本,这两者都是浅拷贝(即复制最外层的容器,副本中的项是原容器的项的引用)。
有时候需要做深拷贝,可以使用copy模块提供的copy和deepcopy函数,分别对任意对象做浅拷贝和深拷贝。
函数的参数是引用时
Python唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言采用这一模式,包括JavaScript、Ruby和Java(Java的引用类型是这样,原始类型按值传参)。
共享传参指函数的形参获得实参引用的副本。也就是说,函数内部的形参是实参的别名。
不要使用可变类型作为参数的默认值
默认值在定义函数时求解,因此默认值变成了函数对象的属性。所以,如果默认值是可变对象,而且修改了他的值,那么后续的函数调用都会受到影响。可变默认值导致的这个问题说明了为什么通常使用None作为接收可变值的参数的默认值。
如果你定义的函数接收可变参数,那就应该谨慎考虑调用方是否期望修改传入的参数。
除非方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。如果不确定,那就创建副本,免得给客户添麻烦。当然,创建副本会消耗一定的CPU和内存。但是,与速度和资源相比,在API中埋下难以察觉的bug显然是更严重的问题。
del和垃圾回收
del语句删除引用,而不是对象。del可能导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用时。重新绑定也可能导致对象的引用数量归零,致使对象被销毁。
Python对不可变类型施加的把戏
共享字符串字面量是一种优化措施,称为驻留(interning)。千万不要依赖字符串或整数的驻留行为!比较字符串或整数是否相等时,应该使用==,而不是is。驻留是Python解释器内部使用的功能。本节讨论的把戏,包括frozenset.copy()的行为,是“善意的谎言”,能节省内存,提升解释器的速度。别担心,这种行为不会给你添任何麻烦,因为只有不可变类型受到影响。或许这些细枝末节的最佳用途是与其他Python程序员打赌,提高自己的胜算。
6.8本章小结
每个Python对象都有标识、类型和值。只有对象的值不时变化。